首发于 Antenna的python学习笔记
切换模式
《Python网络爬虫与信息提取》笔记(12)

li li
搞IT的厨子,是个好工程师,混迹IT行业20年,也许有用。
实例4:股票数据Scrapy爬虫

1.实例介绍
功能描述
- 目标:获取上交所和深交所所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:scrapy
数据网站的确定
获取股票列表:
- 东方财富网: http://quote.eastmoney.com/stocklist.html
获取个股信息:
- 百度股票: https://gupiao.baidu.com/stock/
- 单个股票: https://gupiao.baidu.com/stock/sz002439.html
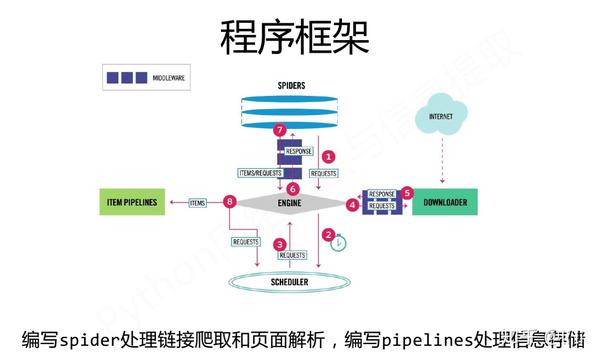

2.实例编写
步骤:
- 步骤1:建立工程和Spider模板
- 步骤2:编写Spider
- 步骤3:编写ITEM Pipelines




















3.实例优化
如何进一步提高scrapy爬虫爬取速度?
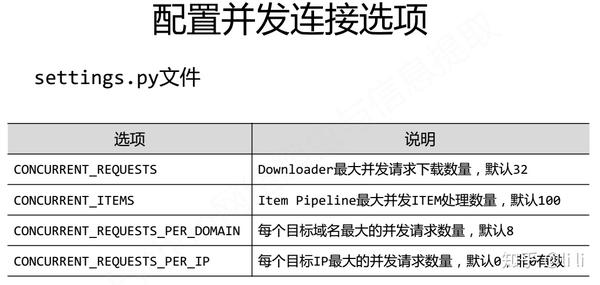

4.小结


5.实践
1.建立工程和Spider模板
(py3MachineLearning) D:\Python网络爬虫与信息提取>scrapy startproject teststock2.编写Spider
(py3MachineLearning) D:\Python网络爬虫与信息提取>cd teststock
(py3MachineLearning) D:\Python网络爬虫与信息提取\teststock>scrapy genspider stocks baidu.com代码:
spiders/stocks.py 课程中的网站发生了变化,我更换了获取股票列表的网站
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
# allowed_domains = ['gupiaozhidao.com']
start_urls = ['http://www.gupiaozhidao.com/quote/allstock.shtml']
def parse(self, response):
for stock_code in response.css('a::text'):
try:
stock = re.findall(r"\((.*?)\)", str(stock_code))[1]
if stock:
url = 'https://gupiao.baidu.com/stock/sh' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except Exception as e:
print("Error:{}".format(e))
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict3.编写pipelines
配置pipelines.py文件,定义对爬取项(Scraped Item)的处理类
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class TeststockPipeline(object):
def process_item(self, item, spider):
return item
class TeststockInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item在settings.py中配置ITEM_PIPELINES选项
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'teststock.pipelines.TeststockInfoPipeline': 300,
}4.执行
(py3MachineLearning) D:\Python网络爬虫与信息提取>scrapy crawl stocks5.可选优化选项
(1)配置headers,防止网站反爬
在settings.py中配置:
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'teststock.middlewares.TeststockDownloaderMiddleware': 543,
'teststock.middlewares.RandomUserAgentMiddleware': 400,
}
USER_AGENT_LIST=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# ---------------------
# 作者:后青春诗ing
# 来源:CSDN
# 原文:https://blog.csdn.net/weixin_42812527/article/details/81366397
# 版权声明:本文为博主原创文章,转载请附上博文链接!在Middlewares.py中配置
from teststock.settings import USER_AGENT_LIST
import random
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
# 下面是随机更换user-agent的代码
# rand_use = random.choice(USER_AGENT_LIST)
# if rand_use:
# request.headers.setdefault('User-Agent', rand_use)
# 观察发现,频繁更换user-agent反而暴露了自己是爬虫
request.headers.setdefault('User-Agent', "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24")(2)控制爬取速度,防止网站反爬
在settings.py中配置,设置自动控制爬取速度:
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
# 参考:scrapy的cookie禁用以及自动限速 https://blog.csdn.net/weixin_42260204/article/details/81096459
AUTOTHROTTLE_ENABLED = True也可以手动设置爬取速度:
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 1观察发现,自动控制的就挺好。
(3)后续优化
后续可以继续研究怎样设置代理、爬取动态网站等,参考资料:
6.执行效果:
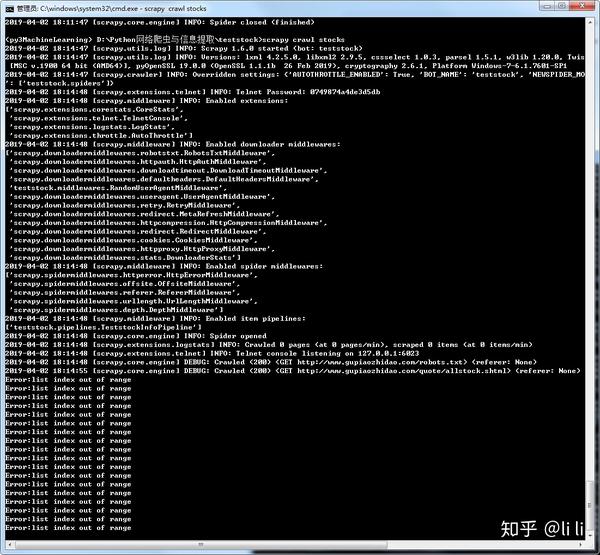

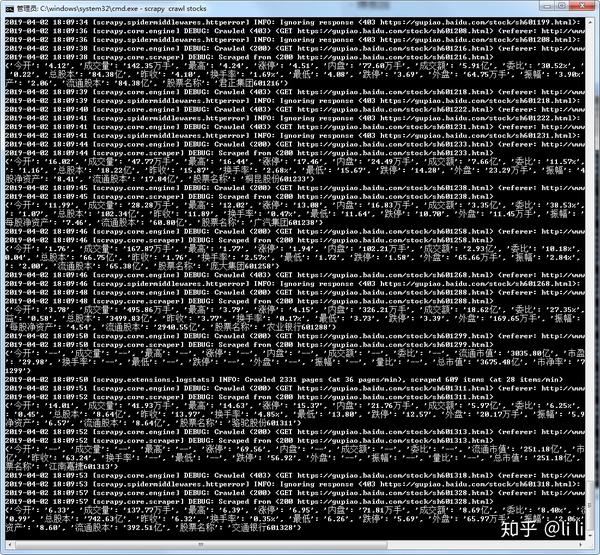

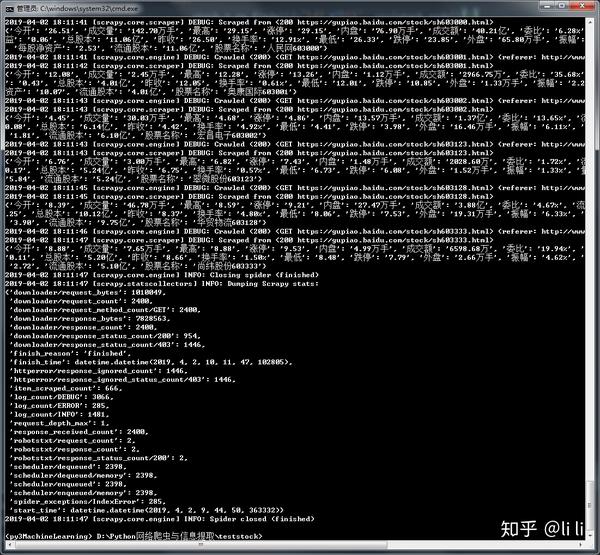

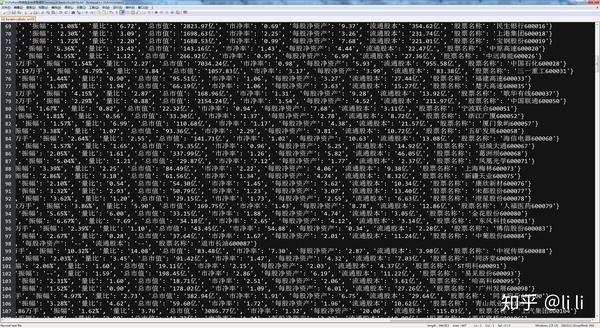

编辑于 2019-04-02 18:18
python爬虫
scrapy
文章被以下专栏收录
