B站爬虫+Python数据分析

「代码分享贴」
有同学找我要代码,拖了好几天了都没发出来,实在抱歉。
因为我的代码很乱,每一个分析都是单独做的,文件命名也是做着做着就放飞自我了......


说着整理整理分享出来,一上手又不知道有什么可整理的,只po代码恐怕大家又很难看得懂,所以我大概写一下分享给大家,都是些比较基础的东西,也算是我自己做个回顾,很多地方都有些问题,如果后续我优化的好我会更新出来。(完整代码在文末)
具体分析内容参见上一期B站数据分析 - 史努比的文章 - 知乎 https://zhuanlan.zhihu.com/p/137660446。
须知:我是初学者,本身也不是CS相关专业的学生,代码底子不是很好。本科学的C语言,大部分的时间都是在写无人机相关的代码。从爬虫到分析,很多技术都是现学现用,能实现功能就未继续深究技术细节。不免有很多愚蠢之处,有更好的实现方法欢迎讨论。
请不同水平的小伙伴们各取所需。
一、爬虫
对于爬虫没有一个基本认识的同学建议参考:
我在我的项目中只使用到了requests和BeautifulSoup库,进阶内容我暂时不需要就没学。
1、爬视频信息(播放量,点赞量等数据)
(1)数据来源:
视频信息来源于B站二级分区下封装的json文件,链接: https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp
链接中有两个参数,在我用“{}”代替的位置。第一个参数rid是二级分区的编号,编号从0-200不定。第二个参数pn是指页数。此外还有一个ps参数是指一页显示的视频信息个数,最大设置为50,保证一次爬取的数据足够多。分区最近有改动,我没有最新的编号,网站开发者模式下可以查到。
这一部分不懂的同学可以参考B站UP主@大野喵渣的爬虫相关视频:(重点是第一期和第二期中一些方法,比较有用)

多线程和多进程:
B站的数据是千万级别的,如果单线程的爬取数据,时间是非常长的,所以需要用到多线程和多进程。我在早期使用的是多进程,用一个进程去爬一个类目的数据,爬完一个类目切换下一个类目。在这个过程中有一个问题就是,如果爬虫过程中出现异常,且你的异常处理模块并没有将此异常过滤而导致该进程中断切换到下一个类目的数据,那么可能会导致缺失大量的数据,且后续的维护十分麻烦。而后我转换思路,先将每一个类目的所有URL按照页码都生成URL库存放到内存中,每次一个进程读取一个URL(50个数据)爬完一页数据切换下一页数据,这样的好处就是即使我的异常处理没能过滤掉异常,我也能将产生异常的URL放到数据库中记录,以便后续看情况补充该部分数据。此处的问题是我沿用了前面的多进程,而没有将多进程换为多线程,但多进程之间快速切换的开销是比多线程大的(猜测,不太懂Python多线程和多进程的实现),小伙伴们在此处可以考虑用多线程。
生成URL库,生成URL库需要知道该类目的视频数量,由于在网页中我识别不到视频数量(更新:有朋友告诉我数量可以找到不用自己算,大家仔细找找),所以我用类似二分查找法手动获取视频数量并生成URL库。(超出页码下限的数据有异常标识)这里可能有同学有疑问,因为新视频在一直发布,这样会不会导致数据漏掉,对的,会,但其实影响不大。最新发布的视频可以最后补充,中间漏掉的不多,每次爬虫一个分区,一个二级分区一般一个小时左右就能爬完,只要视频上传的速度不是太快,影响就不会很大。对分析结论影响就不会很大。最后我的数据和其它第三方机构的数据差别也不是很大。
def find_url(num):
print('开始爬取页面数量')
left = 0
mid = 80000
right = 160000 # 这三个数据定义的目的是
p = mid
for k in range(0, 50000):
time.sleep(0.2)
dis = right - left
r = requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp'.format(num, p))
r.encoding = r.apparent_encoding
data = json.loads(r.text)
# print(left, mid, right)
if len(data['data']['archives']): # 判断第P页是否有数据
right = right
left = mid
p = int((right + mid) / 2)
mid = p
else:
left = left
right = mid
p = int((left + mid) / 2)
mid = p
if len(data['data']['archives']) and dis < 2: # 第P页有数据且“头尾”只差1,结束判断,得到页码
print('aid:{},页数:{},数量:{}'.format(num, p, p * 50))
break
print('页面数量爬取结束')
print('--开始生成URL池--')
Url_Pool = []
for m in range(0, p):
url = "https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp".format(
num, m)
Url_Pool.append(url)
print('--URL池生成结束--')
return Url_Pool(2)爬取数据
现在有了一堆“网址”,就可以开始把数据扒下来看看了。使用requests库将页面数据爬取到本地,并将其解析出来。
r = requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp'.format(num, p))
r.encoding = r.apparent_encoding
data = json.loads(r.text)这里推荐一个json在线解析工具,在测试爬虫的时候挺好用的:

然后解析出来:
for k in range(0, len(data['data']['archives'])):
aid = data['data']['archives'][k]['aid']
title = data['data']['archives'][k]['title'].replace('"', '').replace("'", '')
title = eval(repr(title).replace('\\', ''))
duration = data['data']['archives'][k]['duration']
up_id = data['data']['archives'][k]['owner']['mid']
up_name = data['data']['archives'][k]['owner']['name']
pubdate = data['data']['archives'][k]['pubdate']
coin = data['data']['archives'][k]['stat']['coin']
dan = data['data']['archives'][k]['stat']['danmaku']
star = data['data']['archives'][k]['stat']['favorite']
his_rank = data['data']['archives'][k]['stat']['his_rank']
like = data['data']['archives'][k]['stat']['like']
reply = data['data']['archives'][k]['stat']['reply']
share = data['data']['archives'][k]['stat']['share']
view = data['data']['archives'][k]['stat']['view']
category = data['data']['archives'][k]['tname']
key_words = data['data']['archives'][k]['dynamic'].replace('"', '').replace("'", '')可以注意到在标题和关键词的位置我加入了一些替换操作,这是因为部分视频的标题中出现的特殊符号会影响接下来的存储操作。
在取数的过程中需要注意异常处理,我的处理非常简单,全部用的try—except,尽量处理异常,如果不慎发生异常就将异常的位置存放到数据库中后续再处理。
(3)数据存储
用的数据库是mysql,版本是5.几来着,懒得找了。
python和mysql交互要用到pymysql库,然后按照正常操作连接数据库即可
con = pymysql.connect(host='localhost', port=3306, user='root', passwd='1234', db='bili_info2') # 密码和数据库名字啥的设自己的就行
cursor = con.cursor()接下来是存储,这里我写了两个函数,一个存数,一个记录。有SQL基础的很好懂。
def saveData(d1, d2, d3, d4, d5, d6, d7, d8, d9, d10, d11, d12, d13, d14, d15, d16):
global con, cursor
sql1 = "INSERT INTO video_info(aid,title,up_id,pubdate,duration,`view`,`like`,coin,star,`share`,dan,reply,his_rank,category,key_words) VALUE('{}',\"{}\",'{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}',\"{}\",\"{}\")".format(
d1, d2, d3, d4, d5, d6, d7, d8, d9, d10, d11, d12, d13, d14, d15)
sql2 = "INSERT INTO up_info SET up_id= {},up_name= \"{}\"".format(d3, d16)
cursor.execute(sql1)
cursor.execute(sql2)
con.commit()
def saveR(furl, error=1, said=0): # 出错记录保存
global con, cursor
sql = "INSERT INTO record(url,error,aid) value('{}','{}','{}')".format(furl, error, said)
cursor.execute(sql)
con.commit()库的基本信息我就不放了,上面能看出来有哪些字段。
至此,就能把数据爬到数据库里存着了,补充前文提到的多进程实现,写的很简单,不动的去搜着看一下就能懂。
if __name__ == "__main__":
aa = [这里放分类编号]
po = multiprocessing.Pool(4)
for u in range(0, len(aa)): # len(urlPool)
po.apply_async(find_data, (aa[u],))
print("-----start-----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")2、爬评论
爬评论和爬视频信息基本一致,评论数据在这个网址下: https://api.bilibili.com/x/v2/reply?pn={}&type=1&oid={}&sort=0&_=1584497716933
参数pn依旧指页码,参数oid指视频的av号,这个数据是我爬完视频信息后爬的,所以直接从库中导出需要的AV号就好,AV号改版之后依旧可用。AV号改版对于我这个项目来说基本没有影响。
3、爬弹幕
弹幕的爬取不太一样,需要先从AV号找到cid,再根据cid爬弹幕
例如AV号为1017的视频,在链接: https://api.bilibili.com/x/player/pagelist?aid=1017&jsonp=jsonp下能看到cid为:3772497
data_cid = requests.get('https://api.bilibili.com/x/player/pagelist?aid={}&jsonp=jsonp'.format(av), headers=header)
data_cid.raise_for_status()
data_cid.encoding = data_cid.apparent_encoding
data_cid = json.loads(data_cid.text)
get_dm(av, mid, data_cid['data'][0]['cid'])根据cid,访问 https://api.bilibili.com/x/v1/dm/list.so?oid=3772497,就能看到如下画面:

这时候我们就需要BeautifulSoup库,将信息解析出来。(上文课程中有详细介绍,我就不多说了)
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)
html = requests.get(url, headers=header)
html.raise_for_status()
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'html.parser')
for sibling in soup.d.next_siblings:
p = int(sibling.attrs['p'].split(',')[0].split('.')[0])
update = timestamp_to_time(int(sibling.attrs['p'].split(',')[4]))
content = sibling.string
content = content.replace('"', '').replace("'", '')
content = eval(repr(content).replace('\\', '@'))
content = emoji.demojize(content)
if len(content) <= 49:
saveData(d_mid, d_aid, p, update, content)其中p表示发布位置,update表示发布时间,content表示内容。
再按照和上文一样的存储方式将数据存到数据库中。
二、分析
分析层面用的工具是python的numpy和pandas,教程:
相关的书:

我的这篇文章其实从技术层面的分析逻辑都比较简单,代码都是以实现功能为主,在开销不是特别大情况下没有过分的关注代码的优化。
有一点要提一下:我并不是用python直接从数据库中读数分析,我习惯把数据以csv文件格式存到本地进行分析,我觉得这样在分析的过程中会节约取数的时间。因为在学习初期,需要不断的试错去实现功能,对于某些取数逻辑比较复杂的SQL每次都从数据库中取数相对开销更大。
其实我觉得分析层面没有什么好讲的,对numpy和pandas有一个基本的认识之后看这些分析都是比较基础的,以下讲两个我觉得相对可以分享的点:
1、判定每个UP在每个年份的投稿情况,并统计数量。(有过投稿记为1,没有投稿记为0)
最终效果大概是这样:
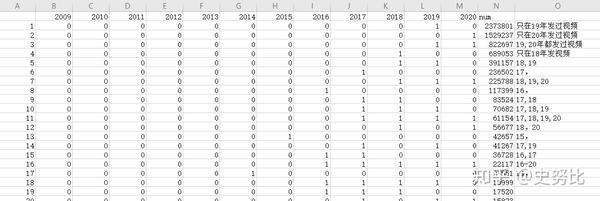

流程如下:
(1)从数据库中取出up_id字段和update字段存放到up_num文件中
(2)读取文件,按照up_id进行分组,在每一个组内进行统计
import pandas as pd
import numpy as np
def analyze(df): # 传入的是一个df,要返回每一个object
return df.groupby(df).size().to_dict()
data = pd.read_csv('E:/SQL_data/up_num.csv', names=['up_id', 'update'])
grouped = data.groupby('up_id')
dict_num = grouped.agg(analyze)['update'].to_dict()
df_num = pd.DataFrame(dict_num)
df_num = df_num.T
df_num.fillna(0, inplace=True)效果如下:
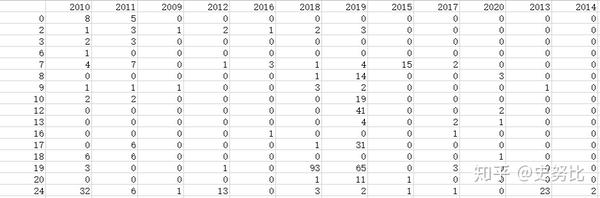

然后根据需求进行分析,比如这里我觉得我要先分析有没有投稿,就可以将条件设置为df>0,这里你可以根据需求进行更改为5或15,我在之前文章中还分析过df>15的情况。这里有一个问题,如何将两行完全相同的dataframe分到一组并计数,这里我用了一个比较蠢的办法是直接将一行转换为列表,然后调用value_counts进行分组。
df1 = (df > 0).astype(int)
data['list'] = data.apply(lambda x: x.tolist(), axis=1)
count = data['list'].value_counts()
count_df = pd.DataFrame(count)其实这时的数据已经能用来分析了,但如果想更直观,可以将列表拆分开(data为上面的输出文件):
a1 = data.iloc[:, 0].map(lambda x: x.split(',')[0][1:2])
a2 = data.iloc[:, 0].map(lambda x: x.split(',')[1][1])
a3 = data.iloc[:, 0].map(lambda x: x.split(',')[2][1])
a4 = data.iloc[:, 0].map(lambda x: x.split(',')[3][1])
a5 = data.iloc[:, 0].map(lambda x: x.split(',')[4][1])
a6 = data.iloc[:, 0].map(lambda x: x.split(',')[5][1])
a7 = data.iloc[:, 0].map(lambda x: x.split(',')[6][1])
a8 = data.iloc[:, 0].map(lambda x: x.split(',')[7][1])
a9 = data.iloc[:, 0].map(lambda x: x.split(',')[8][1])
a10 = data.iloc[:, 0].map(lambda x: x.split(',')[9][1])
a11 = data.iloc[:, 0].map(lambda x: x.split(',')[10][1])
a12 = data.iloc[:, 0].map(lambda x: x.split(',')[11][1])
data1 = pd.concat([a3, a1, a2, a4, a11, a12, a8, a5, a9, a6, a7, a10], axis=1)
data1.columns = ['2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020']
data2 = pd.DataFrame(columns=[])
sum2 = data1['2009'] + data1['2010'] + data1['2011'] + data1['2012'] + data1['2013'] + data1['2014'] + data1['2015'] + data1['2016'] + data1['2017'] + data1['2018'] + data1['2019'] + data1['2020']
data2['sum'] = pd.to_numeric(sum2)
data2['num'] = data['num']
data2 = data2.sort_values(by=['sum'], ascending=False)这会儿就是上文展示最终效果
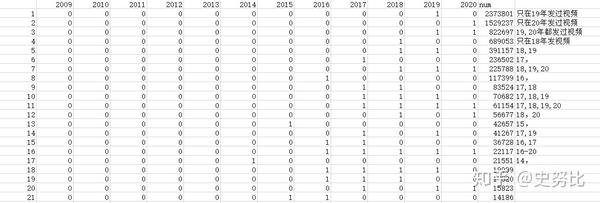

然后手动或者再写代码统计一下就能输出分析结果。
在我把数据爬下来后我就进行过基本的清洗,所以后续的分析大过都不会再清洗数据。
2、头部UP变动分析
头部UP的数据是从网站:
上获得的,本着能偷懒就偷懒的原则,我没有写爬虫,直接复制粘贴到记事本然后写个函数弄出来。
# 将网站上按粉丝量排名的up主,与up分类名单进行分析,得出靠前up的分类
import pandas as pd
def convert1(names): # 获取当月UP粉丝量排名
df1 = pd.read_csv('C:/Users/31248/Desktop/各月topUP/{}.txt'.format(names))
a1 = df1.iloc[:, 0].map(lambda x: x.split('\t')[0])
a2 = df1.iloc[:, 0].map(lambda x: x.split('\t')[1])
a3 = df1.iloc[:, 0].map(lambda x: x.split('\t')[2])
a4 = df1.iloc[:, 0].map(lambda x: x.split('\t')[3])
a5 = df1.iloc[:, 0].map(lambda x: x.split('\t')[4])
a6 = df1.iloc[:, 0].map(lambda x: x.split('\t')[5])
a7 = df1.iloc[:, 0].map(lambda x: x.split('\t')[6])
a8 = df1.iloc[:, 0].map(lambda x: x.split('\t')[11])
data = pd.concat([a1, a2, a3, a4, a5, a6, a7, a8], axis=1)
data.columns = ['UP主', '粉丝量', '粉丝排名', '总播放量', '播放量排名', '视频数', '视频数排名', 'up_id']
data.index = a1.tolist()
data.drop_duplicates(['UP主'], inplace=True) # 删除重复值
data.dropna(axis=0, how='any', inplace=True) # 删除空值
if '#NAME?' in a1.tolist():
data.drop(['#NAME?'], inplace=True) # 清洗异常值
return data
def merge(input_df): # 将两个月的名单以“inner join”的方式合并,然后看依然留在名单中的UP所占白分比
f_category = []
f_num = []
df = pd.read_csv('E:/SQL_data/up_category.csv', header=None, names=['category', 'up_id'], encoding='gbk')
df['up_id'] = df['up_id'].apply(str)
# f_diff = pd.Series(list(set(input_df['up_id']).difference(set(df['up_id']))))
# print(f_diff) # 看奇奇怪怪的东西
f_df = pd.merge(input_df, df, left_on='up_id', right_on='up_id')
grouped = f_df.head(18980).groupby('category')
for name, groups in grouped:
f_category.append(name)
f_num.append(len(groups))
return f_category, f_num
df1812 = convert1(1812)
df2003 = convert1(2003)
category = merge(df1812)[0]
num1812 = merge(df1812)[1]
num2003 = merge(df2003.head(19965))[1]
output = {'category': category, 'num2003': num2003, 'num1812': num1812}
output_df = pd.DataFrame(output)
output_df.index = output_df.loc[:, 'category'].tolist()
output_df = output_df.drop('category', axis=1)
output_df.index.name = 'category'
# df = pd.read_csv('E:/SQL_data/up_category.csv', header=None, names=['category', 'up_id'], encoding='gbk')
# data2 = pd.merge(df1812, df, left_on='up_id', right_on='up_id')
# print(df['up_id'].dtype)
# print(df1812['up_id'].dtype)
# up_category = pd.read_csv('E:/SQL_data/up_category.csv', header=None, names=['category', 'up_id'], encoding='gbk')
其它的我觉得都比较基础,看来看去也找不到比较有意义的,有啥特别有疑问的直接私信问我就好。
附录:完整代码(不想注释了,有啥问题直接私信问我就行)
1、爬取视频信息
# 爬视频信息
import time
import requests
import json
import pymysql #
import multiprocessing
import traceback
con = pymysql.connect(host='localhost', port=3306, user='root', passwd='1234', db='bili_info2') # 密码和数据库名字啥的设自己的就行
cursor = con.cursor()
def saveData(d1, d2, d3, d4, d5, d6, d7, d8, d9, d10, d11, d12, d13, d14, d15, d16):
global con, cursor
sql1 = "INSERT INTO video_info(aid,title,up_id,pubdate,duration,`view`,`like`,coin,star,`share`,dan,reply,his_rank,category,key_words) VALUE('{}',\"{}\",'{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}',\"{}\",\"{}\")".format(
d1, d2, d3, d4, d5, d6, d7, d8, d9, d10, d11, d12, d13, d14, d15)
sql2 = "INSERT INTO up_info SET up_id= {},up_name= \"{}\"".format(d3, d16)
cursor.execute(sql1)
cursor.execute(sql2)
con.commit()
def saveR(furl, error=1, said=0): # 出错记录保存
global con, cursor
sql = "INSERT INTO record(url,error,aid) value('{}','{}','{}')".format(furl, error, said)
cursor.execute(sql)
con.commit()
def timestamp_to_time(date): # 把timestamp格式的时间转换为datetime格式
timeStamp = date
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def find_dict(bb):
rid_dict = {}
for i in range(0, 2):
time.sleep(1) # 延时
left = 0
mid = 80000
right = 160000
p = mid
for k in range(0, 50000):
dis = right - left
r = requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp'.format(bb[i],
p))
# r.encoding = r.apparent_encoding
data = json.loads(r.text)
# print(left, mid, right)
if len(data['data']['archives']):
right = right
left = mid
p = int((right + mid) / 2)
mid = p
else:
left = left
right = mid
p = int((left + mid) / 2)
mid = p
if len(data['data']['archives']) and dis < 5:
print('aid:{},页数:{},数量:{}'.format(bb[i], p, p * 50))
break
rid_dict[bb[i]] = p
return rid_dict
def find_url(num):
print('开始爬取页面数量')
left = 0
mid = 80000
right = 160000 # 这三个数据定义的目的是
p = mid
for k in range(0, 50000):
time.sleep(0.2)
dis = right - left
r = requests.get(
'https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp'.format(num, p))
# r.encoding = r.apparent_encoding
data = json.loads(r.text)
# print(left, mid, right)
if len(data['data']['archives']): # 判断第P页是否有数据
right = right
left = mid
p = int((right + mid) / 2)
mid = p
else:
left = left
right = mid
p = int((left + mid) / 2)
mid = p
if len(data['data']['archives']) and dis < 2: # 第P页有数据且“头尾”只差1,结束判断,得到页码
print('aid:{},页数:{},数量:{}'.format(num, p, p * 50))
break
print('页面数量爬取结束')
print('--开始生成URL池--')
Url_Pool = []
for m in range(0, p):
url = "https://api.bilibili.com/x/web-interface/newlist?&rid={}&type=0&pn={}&ps=50&jsonp=jsonp".format(
num, m)
Url_Pool.append(url)
print('--URL池生成结束--')
return Url_Pool
def find_data(rid):
aaa = {
# 这里是一个字典,分类的rid和对应的页数
}
urlPool = find_url(rid)
print(aaa[rid], len(urlPool))
# noinspection PyBroadException
try:
for j in range(aaa[rid], len(urlPool)):
# noinspection PyBroadException
try:
r = requests.get('{}'.format(urlPool[j]), timeout=500, headers=header)
# r.encoding = r.apparent_encoding
data = json.loads(r.text)
if len(data['data']['archives']) != 0:
# noinspection PyBroadException
try:
for k in range(0, len(data['data']['archives'])):
# noinspection PyBroadException
try:
# noinspection PyBroadException
try:
aid = data['data']['archives'][k]['aid']
title = data['data']['archives'][k]['title'].replace('"', '').replace("'", '')
title = eval(repr(title).replace('\\', ''))
duration = data['data']['archives'][k]['duration']
up_id = data['data']['archives'][k]['owner']['mid']
up_name = data['data']['archives'][k]['owner']['name']
pubdate = data['data']['archives'][k]['pubdate']
coin = data['data']['archives'][k]['stat']['coin']
dan = data['data']['archives'][k]['stat']['danmaku']
star = data['data']['archives'][k]['stat']['favorite']
his_rank = data['data']['archives'][k]['stat']['his_rank']
like = data['data']['archives'][k]['stat']['like']
reply = data['data']['archives'][k]['stat']['reply']
share = data['data']['archives'][k]['stat']['share']
view = data['data']['archives'][k]['stat']['view']
category = data['data']['archives'][k]['tname']
key_words = data['data']['archives'][k]['dynamic'].replace('"', '').replace("'", '')
saveData(aid, title, up_id, pubdate, duration, view, like, coin, star, share, dan,
reply,
his_rank, category, key_words, up_name)
# print(aid, title, up_id, pubdate, duration, view, like, coin, star, share, dan, reply, his_rank, category, key_words, up_name)
saveR(urlPool[j][50:-18], 1, aid)
print('\r爬取中', end="")
except Exception as e:
if len(e.args) >= 2:
if int(e.args[0]) == 1062:
pass
else:
pass
else:
traceback.print_exc()
aid = data['data']['archives'][k]['aid']
title = 'error'
title = eval(repr(title).replace('\\', ''))
duration = data['data']['archives'][k]['duration']
up_id = data['data']['archives'][k]['owner']['mid']
up_name = data['data']['archives'][k]['owner']['name']
pubdate = data['data']['archives'][k]['pubdate']
coin = data['data']['archives'][k]['stat']['coin']
dan = data['data']['archives'][k]['stat']['danmaku']
star = data['data']['archives'][k]['stat']['favorite']
his_rank = data['data']['archives'][k]['stat']['his_rank']
like = data['data']['archives'][k]['stat']['like']
reply = data['data']['archives'][k]['stat']['reply']
share = data['data']['archives'][k]['stat']['share']
view = data['data']['archives'][k]['stat']['view']
category = data['data']['archives'][k]['tname']
key_words = 'error'
saveData(aid, title, up_id, pubdate, duration, view, like, coin, star, share,
dan, reply,
his_rank, category, key_words, up_name)
saveR(urlPool[j][50:-18], -1, aid)
except:
continue
except:
traceback.print_exc()
saveR(urlPool[j][50:-18], -2)
else:
return 0
except:
traceback.print_exc()
saveR(urlPool[j][50:-18], -3) # -2代表爬取错误
saveR(urlPool[j][50:-18], 8)
except:
traceback.print_exc()
saveR('error', -4)
if __name__ == "__main__":
aa = [#放分类编号]
po = multiprocessing.Pool(4)
for u in range(0, len(aa)): # len(urlPool)
po.apply_async(find_data, (aa[u],))
print("-----start-----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
2、爬取评论
import time
import requests
import json
import pymysql
import multiprocessing
import pandas as pd
import traceback
con = pymysql.connect(host='localhost', port=3306, user='root', passwd='1234', db='bili_info3')
cursor = con.cursor()
header = {
}
def timestamp_to_time(date):
timeStamp = date
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def saveData(d3, d4, d5, d6, d7, d8=0, d9=946974):
global con, cursor
sql1 = "INSERT INTO remark1(num,rnum,aid,`mid`,sex,reply_time,vip,`sign`,up_id) value({},{},{},{},'{}','{}',{},{},{})".format(0, 0, d3, d4, d5, d6, d7, d8, d9)
cursor.execute(sql1)
con.commit()
def saveR(furl, error=1, said=0): # 出错记录保存
global con, cursor
sql = "INSERT INTO record(url,error,aid) value('{}','{}','{}')".format(furl, error, said)
cursor.execute(sql)
con.commit()
def find_remark(faid):
save_mid = 0
for p in range(1, 10000):
time.sleep(1.2)
try:
rr = requests.get('https://api.bilibili.com/x/v2/reply?pn={}&type=1&oid={}&sort=0&_=1584497716933'.format(p, faid),
headers=header)
rr.encoding = "utf8"
data = json.loads(rr.text)
if save_mid == data['data']['replies'][0]['member']['mid']:
break
else:
for i in range(0, len(data['data']['replies'])):
mid = data['data']['replies'][i]['member']['mid']
sex = data['data']['replies'][i]['member']['sex']
vip = data['data']['replies'][i]['member']['vip']['vipType']
reply_time = timestamp_to_time(data['data']['replies'][i]['ctime'])
sign = 0 # 主楼评论
# print(mid, sex, vip, reply_time)
saveData(faid, mid, sex, reply_time, vip, sign)
if data['data']['replies'][i]['replies']:
for j in range(0, len(data['data']['replies'][i]['replies'])):
mid = data['data']['replies'][i]['replies'][j]['member']['mid']
sex = data['data']['replies'][i]['replies'][j]['member']['sex']
vip = data['data']['replies'][i]['replies'][j]['member']['vip']['vipType']
reply_time = timestamp_to_time(data['data']['replies'][i]['replies'][j]['ctime'])
sign = 1 # 副楼回复
# print(mid, sex, vip, reply_time)
saveData(faid, mid, sex, reply_time, vip, sign)
print('当前aid:{},当前页数:{}'.format(faid, p))
save_mid = data['data']['replies'][0]['member']['mid']
# print(save_mid)
page = p
print(page)
except:
traceback.print_exc()
break
if __name__ == "__main__":
# find_remark()
data = pd.read_csv('E:/SQL_data/huanong.csv', header=None, encoding='gbk', names=['aid'])
po = multiprocessing.Pool(4)
for i in range(0, len(data)):
po.apply_async(find_remark, (data.iloc[i]['aid'],))
print("-----start-----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")
3、爬取弹幕
import requests
import sys
import importlib
from bs4 import BeautifulSoup
import time
import pandas as pd
import pymysql
import json
import traceback
import multiprocessing
import datetime
import emoji
importlib.reload(sys)
con = pymysql.connect(host='localhost', port=3306, user='root', passwd='1234', db='bili_info3')
cursor = con.cursor()
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
def saveData(d1, d2, d3, d4, d5):
global con, cursor
sql1 = "INSERT INTO dan_mu1(mid,aid,s_p,remarkTime,content) VALUE(\"{}\",\"{}\",\"{}\",\"{}\",\"{}\")".format(d1, d2, d3, d4, d5)
cursor.execute(sql1)
con.commit()
def timestamp_to_time(date):
timeStamp = date
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def get_cid(av, mid):
data_cid = requests.get('https://api.bilibili.com/x/player/pagelist?aid={}&jsonp=jsonp'.format(av), headers=header)
data_cid.raise_for_status()
data_cid.encoding = data_cid.apparent_encoding
data_cid = json.loads(data_cid.text)
get_dm(av, mid, data_cid['data'][0]['cid'])
def get_dm(d_aid, d_mid, oid):
# noinspection PyBroadException
try:
if 9 >= int(str(datetime.datetime.now())[10:13]) >= 0: # 深夜降速
time.sleep(2)
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)
html = requests.get(url, headers=header)
html.raise_for_status()
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'html.parser')
for sibling in soup.d.next_siblings:
# noinspection PyBroadException
try:
p = int(sibling.attrs['p'].split(',')[0].split('.')[0])
update = timestamp_to_time(int(sibling.attrs['p'].split(',')[4]))
content = sibling.string
content = content.replace('"', '').replace("'", '')
content = eval(repr(content).replace('\\', '@'))
content = emoji.demojize(content)
if len(content) <= 49:
saveData(d_mid, d_aid, p, update, content)
else:
continue
except:
# traceback.print_exc()
continue
print('over')
except:
traceback.print_exc()
pass
if __name__ == '__main__':
data = pd.read_csv('E:/SQL_data/choose_up_aid2.csv', header=None, names=['mid', 'aid'])
po = multiprocessing.Pool(6)
for u in range(0, len(data)): # len(urlPool)
po.apply_async(get_cid, (data.iloc[u]['aid'], data.iloc[u]['mid'],))
print("-----start-----")
po.close() # 关闭进程池,关闭后po不再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("-----end-----")