博文
一个很简单的汉语自动分词系统
||
最近自然语言理解课程刚结课,我就惆怅了...
汉语自动分词是目前中文信息处理领域公认的一大难题,也是自然语言理解研究领域中最基本的一个环节。中文自动分词就是将用自然语言书写的文章、句段经计算机处理后,以词为单位逐词输出,为紧随其后的加工处理提供先决条件,如图1所示。可见,中文自动分词是自然语言处理的第一个步骤,其重要性勿庸置疑。
然而,汉语自动分词存在很大的挑战。命名实体识别、集外词处理和歧义消解是三个最根本又很棘手的问题。这里所谓的命名实体指的是人名、机构名、地名以及其他所有以名称为标识的实体。例如,“计算技术研究所”,“斯琴高娃”,“布宜诺斯艾利斯”,要是在训练集中没有包含这些词的先验知识,那么将它们完整从句子中切分出来是很困难的。集外词也叫做未登录词。这些词的出现是由于数据集范围的局限性以及新词的产生。它们包括了部分的命名实体、网络用语等,如何对这些未能从数据集中获得知识的词切分,依旧值得认真研究。常见的两种汉语分词的歧义有:1)交集型切分歧义。例如,给定一个输入句子——“结合成分子”,由于其中的“结合”、“合成”、“成分”和“分子”都能构成词,因此对切分来说造成了一定的困难;2)组合型歧义。例如“门把手弄坏了”,由于字之间的不同组合,可能存在的分词结果有:“门/把/手/弄坏了”和“门/把手/弄/坏/了”。尽管存在这么多的难以处理的问题,新的分词方法还是在不断被发掘。
本文实现了一个基于前向、后向最大匹配算法的分词系统。对于输入一个的句子或一篇文章,首先,我们用于最大匹配算法在事先构建的字典里找寻最大匹配的词,并记录对应的词性。然后,对相应的分词结果进行切分。最后,通过一个简单的演示系统来直观的展示前向匹配算法与后向匹配算法之间的不同,并给出最终获得的分词结果。

图 1自然语言理解及其应用
说到中文自动分词的国内研究,从起步至今已有二十余个年头。有关自动分词的文献也是层出不穷,由于中文自动分词技术覆盖的学科知识较全面,有实力对其进行深入持续研究并获得不俗成果的科研机构国内只有为数不多的几家,如中科院、北大、清华、北京语言学院、东北大学、IBM研究院、微软中国研究院等。
获得的一些主要成果如下:
1980年前后,我国在中文自动分词方面取得初步进展之后,国内的学者开始对中文分类自动标引技术[1]进行深入研究,目前已经能通过对文中反映主题的关键词的自动抽取与筛选,实现主题自动标引。
1983 年,北航梁南元副教授第一个完成实用的 CDWS 自动分词系统[2],实现了对 2500 万字的现代汉语词频统计工作。此后又有数个系统问世,并提出了 12种分词方法。
1987 年,作为国家“七五”攻关课题之一的现代汉语分词规范和自动分词方法,已由北京航空航天大学、北京语言学院等十几家单位同时承担,并取得了可喜的进展,目前正向实用化发展。
1990 年末,北京师范大学以何克抗教授为首的课题组完成了实用的自动分词系统。
1995 年,叶新明通过对现有中文自动分词算法的分析,提出了适于中文文献的自动分词算法,该算法通过建立机读词表,以《中图法》作为分类标准,对中文文献实现了自动分类,在财政金融类文献上的测试准确率达到 79%。
根据 1998 年初,由国家科委基础研究高技术司、国家高技术 863 计划智能计算机系统主题专家组、全国信标委非键盘输入分技术委员会组织的机器翻译系统、自动分词与标注、汉字识别系统、语音识别系统的测评结果,对 229 个测试点的交集型歧义切分字段定点测试,北京工业大学计算机学院提交的系统,准确率为68.56%;对 20 个测试点的多义组合型歧义切分字段定点测试,北京工业大学计算机学院提交的系统,准确率为 40.00%。
1998 年的 863 测试包括自动分词和词性标注[3]两项内容,在自动分词方面没有明显进展。中国科学院计算技术研究所在多年研究基础上,耗时一年研制出了基于多层隐马模型的汉语词法分析系统 ICTCLAS[6](Institute of Computing Technology,Chinese Lexical Analysis System),该系统的功能有:中文分词,词性标注,未登录词识别。分词正确率高达 97.58%(最近的 973 专家组评测结果),基于角色标注的未登录词识别能取得高于 90%的召回率,其中中国人名的识别召回率接近 98%,分词和词性标注处理速度为 31.5KB/s。
分词算法研究是汉语自动分词的重点与难点,仅自80 年代以来,成果得以公布的自动分词方法和算法就有数十种[4-7],其中在下文会提及的有正向最大匹配法 FMM、逆向最大匹配法 BMM。
最大匹配算法主要包括正向最大匹配算法、逆向最大匹配算法、双向匹配算法等。 其主要原理都是切分出单字串,然后和词库进行比对,如果是一个词就记录下来, 否则通过增加或者减少一个单字,继续比较,一直还剩下一个单字则终止,如果该单字串无法切分,则作为未登录处理。下面我们主要介绍前向最大匹配与后向最大匹配算法。
假设句子:S=c1c2…cn,某一词:wi= c1c2…cn,m为词典中最长词的字数。
FMM算法:
(1) 令i=0,当前指针pi指向输入字串的初始位置,执行下面的操作:
(2) 计算当前指针pi到字串某段的字数(即未被切分字串的长度)n,如果n=1,转(4),结束算法。否则,令m=词典中最长单词的字数,如果n<m,令m=n;
(3) 从当前pi起取m个汉字座位词wi,判断:
a) 如果wi确实是词典中的词,则在wi后添加一个切分标志,转(c);
b) 如果wi不是词典中的词且wi的长度大于1,讲wi从右端去掉一个字,转(a),步;否则(wi的长度等于1),则在wi后添加一个切分标志,将wi作为单字词添加到词典中,执行(c)步;
c) 根据wi的长度修改指针pi的位置,如果pi,指向字串末端,转(4),否则,i=i+1,返回(2)。
(4) 输出切分结果,结束分词程序。
后向最大匹配的算法与前向最大匹配算法相类似,不同之处在于:
1. 它是从后往前找最长的匹配字串;
2. 这从当前字串的前部去掉一个字来找匹配。
我们以下面一个例子来说明它们两者之间的不同之处。
例:假设词典中最长单词的字数为 7。
输入字串:他是研究生物化学的。
切分过程:他是研究生物化学的。
FMM 切分结果:他/ 是/ 研究生/ 物化/ 学/ 的/。
BMM 切分结果:他/ 是/ 研究/ 生物/ 化学/ 的/。
总的来说,基于最大匹配算法的分词方法的特点是:
1. 优点:
a) 程序简单易行,开发周期短;
b) 仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源;
2. 弱点:
a) 歧义消解的能力差;
b) 切分正确率不高,在95%左右。
本文实现了一个基于最大匹配的汉语分词系统。下面从算法描述和模块流程来说明此系统。
我们的分词系统共分为三个模块:用户查询模块、FMM/BMM分词模块与分词结果输出模块。
本文考虑用户的实际需求,通过设计友好的用户交流界面来让机器于用户进行互动,最后达到分词的效果,设计分词系统界面如图2所示:

|
|
|
|
图 2分词系统界面
其中①处为用户输入待分词的句子处。
4.1.2 FMM/BMM分词模块

图 3分词模块
4.1.3 分词结果输出模块
|
图 4输出模块 |
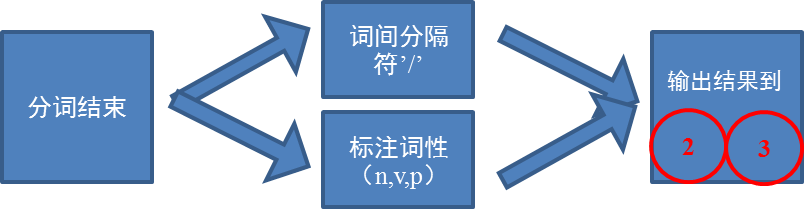
5 实验结果与分析
5.1 实验
实验环境设置如下:
1. MFC 界面,VS2008编程平台,Win7操作系统,内存2.92G,主频2.3G。
2. 使用现代汉语语料库词语作为字典,其中每个词的出现次数大于50次。共16254个词+8种标点符号。词典中部分词语标注结果如图5。
第一个实验:我们这里使用《京华烟云》中的片段来说明FMM与BMM分词结果,并且在FMM的输出结果中给出了词性标注,见图6。
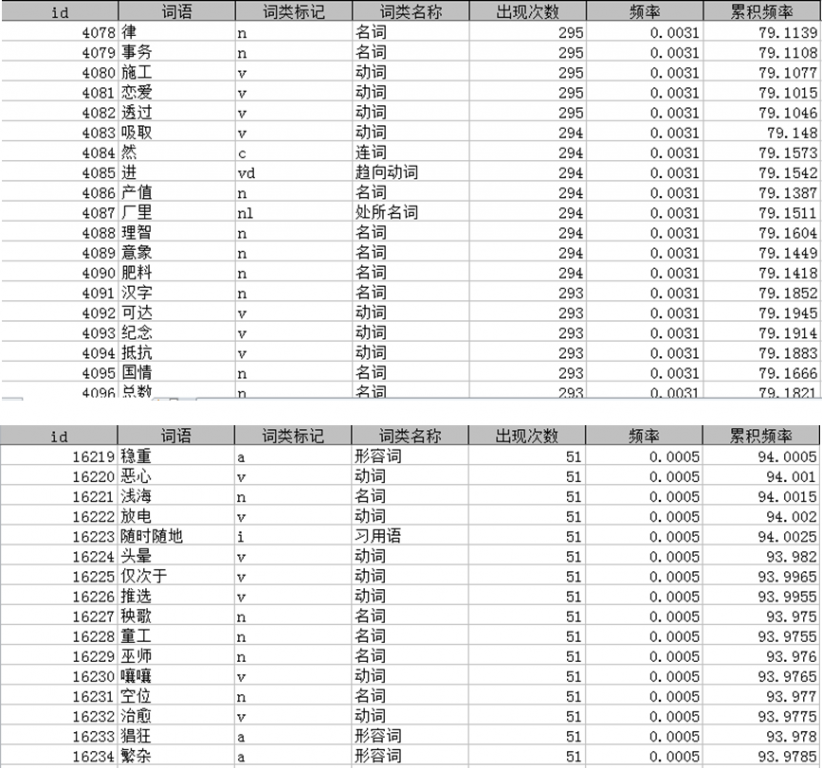
图 5现代汉语语料库部分词语以及词性标记
第二个实验:图7中通过一个简单的例子来说明分词中存在的歧义:
输入:人的一生是有限的,而为人民服务是无限的。
FMM:人/ 的/ 一生/ 是/ 有限/ 的/ ,/ 而/ 为人/ 民/ 服务/ 是/ 无限/ 的/ 。
BMM:人/ 的/ 一生/ 是/ 有限/ 的/ ,/ 而/ 为/ 人民/ 服务/ 是/ 无限/ 的/ 。
其中加黑的部分为歧义字段。
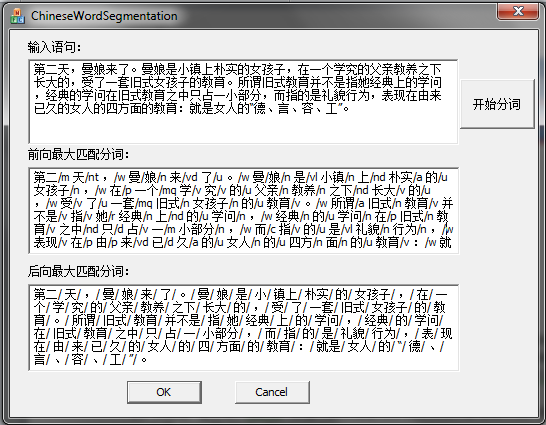
图 6林语堂《京华烟云》部分分词结果
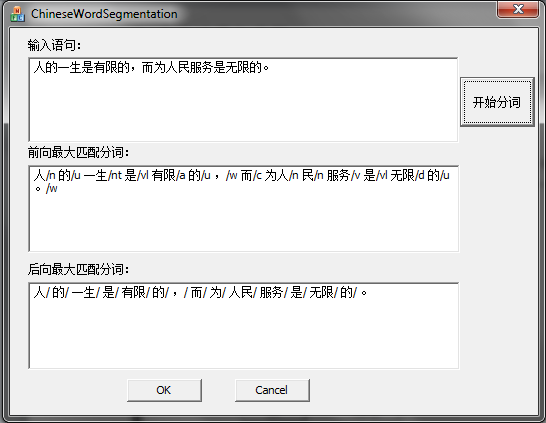
图 7 FMM与BMM的分词歧义
第三个实验:一段网易新闻的分词以及词性标注结果。
测试语料:
专辑评测:凤凰传奇的第一张唱片“月亮之上”在误打误撞之下成为白金继彩铃歌曲,并在汽车音响中大获全胜。尽管他们在第二张“吉祥如意”的操作依样画葫芦,却悄悄的加大市场的覆盖面。只是在曲风没有很大新突破的情况下,叫座不叫好。但我们可以看到,他们开始变得越来越亲民了。回归到这张“最炫民族风”,唱片公司更是祭出了“民族流行”的旗帜,大打流行牌。的确,新专辑在编曲上比以前的作品更多元化了,也加入了更多原生态的音乐元素,制作也更为丰富,歌曲的完成度也相当的高。可以说,这张“最炫民族风”就是在维持民族腔调的基础上,用混搭做了讨巧的改变而已。就像芭蕾舞版的“红色娘子军”,换汤不换药的点到即止。而“最炫民族风”这张专辑最讨巧的地方,在于对民谣、摇滚、慢嗨、舞曲、嘻哈和新时代等元素的继承发展的同时,又能恰到好处的保持歌曲本身的民歌韵味。比起现在很多的流行歌手一味的卖曲风抓时尚元素的现成粗暴做法,凤凰传奇显然更为细腻而简洁。专辑标题曲“最炫民族风”的旋律煽情,朗朗上口,极具流行性。“高山槐花开”则结合了民乐、新世纪元素,旋律行云流水,让玲花悠游的嗓音穿梭其中,将人带入一片世外桃源。“天蓝蓝”是一副云淡风轻的写意山水画,融合了说唱和节奏布鲁斯。此外作为唱片唯一的环保歌曲,体现了凤凰传奇的“绿色自然主义”。一张专辑下来,草原上风高云清、天苍野茫的爽朗的味道大刀阔斧的渲染开来,首首耐听却丝毫不口水。民族的加上流行元素,的确是比流行歌手的中国风更原生态。
FMM分词:
专/a 辑/评/v 测/v :/w 凤凰/n 传奇/n 的/u 第一/m 张/q 唱片/n “/w 月亮/n 之上/nd ”/w 在/p 误/v 打/v 误/v 撞/v 之下/nd 成为/v 白/a 金/n 继/v 彩/n 铃/n 歌曲/n ,/w 并/c 在/p 汽车/n 音响/n 中/nd 大/a 获/v 全/a 胜/v 。/w 尽管/d 他们/r 在/p 第二/m 张/q “/w 吉/祥/如/v 意/n ”/w 的/u 操作/v 依/v 样/n 画/n 葫芦/n ,/w 却/d 悄悄/a 的/u 加大/v 市场/n 的/u 覆盖/v 面/n 。/w 只是/d 在/p 曲/n 风/n 没有/v 很/d 大/a 新/a 突破/v 的/u 情况/n 下/nd ,/w 叫/v 座/q 不/d 叫/v 好/a 。/w 但/c 我们/r 可以/vu 看到/v ,/w 他们/r 开始/v 变/v 得/u 越来越/d 亲/n 民/n 了/u 。/w 回归/v 到/v 这/r 张/q “/w 最/d 炫/民族/n 风/n ”/w ,/w 唱片/n 公司/n 更是/vl 祭/v 出/vd 了/u “/w 民族/n 流行/v ”/w 的/u 旗帜/n ,/w 大/a 打/v 流行/v 牌/n 。/w 的确/d ,/w 新/a 专/a 辑/在/p 编/v 曲/n 上/nd 比/p 以前/nt 的/u 作品/n 更/d 多元/n 化/k 了/u ,/w 也/d 加入/v 了/u 更/d 多/a 原生/v 态/n 的/u 音乐/n 元素/n ,/w 制作/v 也/d 更为/d 丰富/a ,/w 歌曲/n 的/u 完成/v 度/n 也/d 相当/d 的/u 高/a 。/w 可以说/v ,/w 这/r 张/q “/w 最/d 炫/民族/n 风/n ”/w 就是/d 在/p 维持/v 民族/n 腔/n 调/v 的/u 基础上/nl ,/w 用/v 混/v 搭/v 做/v 了/u 讨/v 巧/a 的/u 改变/v 而已/u 。/w 就/d 像/v 芭蕾舞/n 版/n 的/u “/w 红色/n 娘/n 子/n 军/n ”/w ,/w 换/v 汤/n 不/d 换/v 药/n 的/u 点/n 到/v 即/d 止/v 。/w 而/c “/w 最/d 炫/民族/n 风/n ”/w 这/r 张/q 专/a 辑/最/d 讨/v 巧/a 的/u 地方/n ,/w 在于/v 对/p 民/n 谣/、/w 摇/v 滚/v 、/w 慢/a 嗨/e 、/w 舞/v 曲/n 、/w 嘻/哈/o 和/c 新/a 时代/nt 等/u 元素/n 的/u 继承/v 发展/v 的/u 同时/c ,/w 又/d 能/vu 恰/d 到/v 好处/n 的/u 保持/v 歌曲/n 本身/n 的/u 民歌/n 韵/n 味/n 。/w 比起/v 现在/nt 很多/a 的/u 流行/v 歌手/n 一味/d 的/u 卖/v 曲/n 风/n 抓/v 时/nt 尚/d 元素/n 的/u 现/v 成/v 粗暴/a 做法/n ,/w 凤凰/n 传奇/n 显然/a 更为/d 细腻/a 而/c 简/a 洁/。/w 专/a 辑/标题/n 曲/n “/w 最/d 炫/民族/n 风/n ”/w 的/u 旋律/n 煽/情/n ,/w 朗/朗/上/nd 口/n ,/w 极/d 具/v 流行/v 性/k 。/w “/w 高山/n 槐/花/n 开/v ”/w 则/c 结合/v 了/u 民/n 乐/v 、/w 新/a 世纪/nt 元素/n ,/w 旋律/n 行/v 云/n 流水/n ,/w 让/p 玲/花/n 悠/游/v 的/u 嗓音/n 穿/v 梭/其中/nd ,/w 将/d 人/n 带/v 入/v 一片/mq 世/nt 外/nd 桃/n 源/n 。/w “/w 天/nt 蓝/a 蓝/a ”/w 是/vl 一/m 副/h 云/n 淡/a 风/n 轻/a 的/u 写意/n 山水/n 画/n ,/w 融合/v 了/u 说/v 唱/v 和/c 节奏/n 布/n 鲁/斯/r 。/w 此外/c 作为/v 唱片/n 唯一/a 的/u 环/n 保/v 歌曲/n ,/w 体现/v 了/u 凤凰/n 传奇/n 的/u “/w 绿色/n 自然/a 主义/n ”/w 。/w 一/m 张/q 专/a 辑/下来/vd ,/w 草原/n 上/nd 风/n 高/a 云/n 清/a 、/w 天/nt 苍/野/a 茫/的/u 爽朗/a 的/u 味道/n 大刀/n 阔/a 斧/n 的/u 渲染/v 开来/v ,/w 首/n 首/n 耐/v 听/v 却/d 丝毫/n 不/d 口/n 水/n 。/w 民族/n 的/u 加上/v 流行/v 元素/n ,/w 的确/d 是/vl 比/p 流行/v 歌手/n 的/u 中国/ns 风/n 更/d 原生/v 态/n 。/w
尽管 FMM 是最常用的中文自动分词的解决方案,不过,该算法存在几个明显的缺陷,直接限制了其在搜索系统中的实际应用。
为了在效率与词长之间作出平衡,FMM 算法必须预先设定一个指定的匹配词长的初始值,这可能会导致以下两种情况:
(1) 词长过短时,待识别长词被截断。若词长被设成 5,则意味着它只能切分出长度小于或等于 5 的词。当词的词长大于 5 时,例如“小布尔乔维亚情调”,我们最多只能取出其中的 5 个字与词库里的词相匹配,用正向最大匹配法切分后得到的结果是“小布尔乔维”,显然词库里不可能存在这样的词组。此时,我们就无法正确地划分出“小布尔乔维亚情调”这样的词长大于 5 的词。
(2) 词长过长时,分词效率较低。为了避免上述情况的出现,可以选择把最大词长尽可能地加长,但是,这样就会凸显出效率方面的不足。设想当最大词长被设成 8 时,必须截取长度为 8 的词,每次减一字,和词典里的词表进行比对看是否匹配,然而大多数词的词长却只有两三个字,这意味着前 5 次的匹配算法是徒劳的。
因此,必须兼顾词长与效率,既要求分词尽量准确,又要求词长不能太长。
效率低是使用 FMM 算法必然会出现的一个问题。设想,即便词长可以设定得相当短,例如,在不牺牲分词的准确率的前提下,设词长为 5,然而当大多数词的词长为 2 时,至少有 3 次的匹配算法是浪费掉的。理论上,这些被浪费掉的匹配时间是可以通过对算法的改进来弥补的。
中文是世界上最复杂的自然语言之一,表达方式繁多且语法精妙,以计算机的逻辑很难恰如其分地理解,因此必然会带来分词的歧义性。如下例所示:
输入文本:“研究生涯”
FMM 分词结果:“研究生/涯”
BMM 分词结果:“研究/生涯”
词的歧义性使得我们在使用最大匹配算法分词时可能会产生模拟两可的结果,且使用 FMM 与 BMM 分词可能会产生截然不同的结果。尽管使用回溯法或其他方法来计算词的使用频率,可减少出现歧义的可能性,但是类似上文中的例子这样的结果往往是不可避免的。
本文设计了一个基于最大匹配算法的分词系统。在简单的MFC用户界面下,基于现代汉语语料库词典,实现FMM和BMM算法,并比较了两者,来分析它们用于分词时存在的歧义性;然后还给出了词性标注的结果。最后,我们实验地分析了这个分词系统的效果,发现FMM存在长度限制、效率低、掩盖分词歧义等缺点。因此给将来做FMM的优化算法提供了思路。
[1] 孙巍.一种面向中文信息检索的汉语自动分词方法[J].现代图书情报技术.2006,7: 33 –36.
[2] 傅立云,刘新. 基于词典的汉语自动分词算法的改进[J]. 情报杂志. 2006,1: 40–41.
[3] 尹锋. 汉语自动分词研究的现状与新思维[J]. 现代图书情报技术. 1998, 4:87-89.
[4] 梁南元. 汉语计算机自动分词知识[J]. 中文信息学报. 2000, 4 (2): 37-43.
[5] 张国煊, 王小华, 周必水. 快速书面汉语自动分词系统及其算法设计[J]. 计算机研究与发展. 2000, 30 (1): 61-65
[6] 吴胜远. 一种汉语分词方法[J]. 计算机研究与发展. 2003, 33 (4): 306-311.
[7] 郑婧,孙卫. 国内自然语言处理技术研究与应用的状态[J]. 数字图书馆论坛.2008, 7(2): 46-48.
可执行程序.zip
https://blog.sciencenet.cn/blog-733228-577338.html
上一篇: 颜色相关直方图——原理,模型与方法
下一篇: 一般性物体的分割方法介绍(一)
0
该博文允许注册用户评论 请点击登录 评论 (6 个评论)
![]()
严灿祥
- 加为好友
- 给我留言
- 打个招呼
- 发送消息
全部作者的其他最新博文
- • 一般性物体的分割方法(二)
- • 计算机视觉...
- • 一般性物体的分割方法介绍(一)
- • 颜色相关直方图——原理,模型与方法
全部精选博文导读
- • 科学网2024年3月十佳博文榜单公布!
- • 导师:年年审毕业论文,总有这些问题!
- • 再次逐项归纳学位论文的写法
- • 浙江大学胡宁等综述:用于先进电生理记录的有源微纳生物电子器件
- • 同一伦理委员会的批准号能否用于近250篇不同临床研究论文?
- • 有钱有技术,人类能实现如期登月吗?
相关博文
- • [转载]【喜报】《智能科学与技术学报》14位编委入选2023“中国高被引学者”
- • 孙明瑜教授入选2023年爱思唯尔高被引学者
- • [转载]我校曾荣昌教授连续3年入选爱思唯尔“中国高被引学者”
- • 喜讯!16位NML编委入选2023爱思唯尔“中国高被引学者”榜单
- • [转载]JAS 103名专家入选爱思唯尔2023“中国高被引学者”榜单
- • [转载]祝贺!经济学院何凌云教授连续四年入选Elsevier“中国高被引学者”